Atomic locks in Laravel explained for humans
Atomic Locking is a way of saying, "only one person can perform X operation at a time". In engineering terminology, it's a way to handle race conditions. Race conditions occur when multiple processes attempt to access the same resource at the same time, and this some times can cause problems.
Real world scenario
Let's understand the problem and the solution on high level, and then we are going to dive into the code.
The problem
We have a web hosting application where users can perform server actions from our app, like Laravel Forge. One of these actions is a button "Deploy", and when you click that, your site is being deployed on the server. (Multiple steps happen there, for example server pulls latest repository's branch files, does some bash magic to manage zero downtime deployments and at the end finally the deployment is ready).
That's great, but on our app, multiple users can manage the same site. What if 2 users try to deploy the same site, at the same time? We decided that we do not want 2 deployments to happen at the same time, because that can screw things up.
The solution (high level explanation)
Here atomic locks come and solve the above issue. So the high level logic is to "lock" the deploy operation, by a unique identifier. So if other process tries to "get" the lock, it won't be possible, until the first process releases the lock.
Don't know if that helps, that's not any official terminology or something, but on my mind, I like to think of it like that:
- The first process/user (A) locks the action by a unique identifier (ex: 'lock_deploying_site_12345', where 12345 is the ID of the site)
- The same process/user (A), because is the first one, gets the key for the lock, so it can "unlock" it, and runs the actual code (the deploy business logic code). Whoever can unlock the ... lock, it means that can execute the actual code.
- Now while the above process executes the code, if another process/user (B) comes and tries to do the same thing, it can not "unlock" the lock for the same identifier 'lock_deploying_site_12345', so it will get a response like "hey another user/process is doing the same thing right now, please try again later".
- When process A finish executing, it releases the lock. So now there is no more locking for this action, which means that a new process can normally start the procedure again. A lock is released only by the process that started the locking procedure, or automatically after X time (more on that later).
By locking, think of it like a flag. It's either true or false, it's simple as that.
So if lock_deploying_site_12345 = true, then no other process can deploy the same site. If it is false (basically doesn't exist), then other processes can "unlock" and initialise the locking. Hopefully it makes sense.
If the above make sense to you, code will be extremely easily to understand.
Let's now dive into some code
Suppose we have this simple controller responsible for deploying our site.
public function deploy(Site $site)
{
Gate::authorize('deploy', $site);
// Deploying business logic, could be whatever
// This takes some time to finish
// $site->deploy()
return response([
'success' => true
]);
}This is the problematic one, because if 2 users try to deploy the same site at the same time, that could cause server problems.
Laravel provides us a very elegant way of applying Atomic Locking. See how we can improve this:
public function deploy(Site $site)
{
Gate::authorize('deploy', $site);
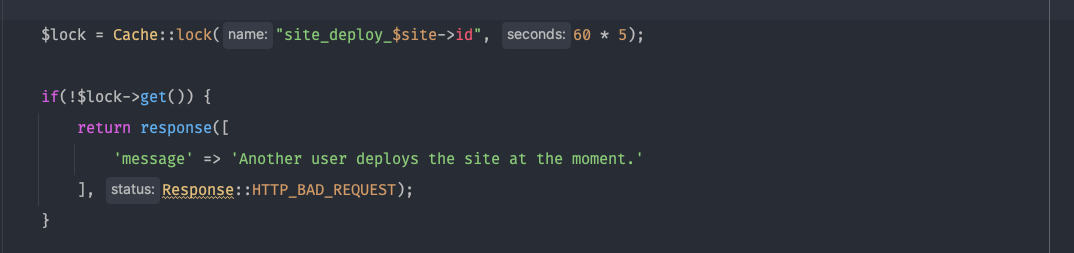
$lock = Cache::lock("site_deploy_$site->id", 60 * 5);
if(!$lock->get()) {
return response([
'message' => 'Another user deploys the site at the moment.'
], Response::HTTP_BAD_REQUEST);
}
// Deploying business logic, could be whatever
// This takes some time to finish
// $site->deploy()
$lock->release();
return response([
'success' => true
]);
}Explanation:
$lock = Cache::lock("site_deploy_$site->id", 60 * 5);We specify here for which lock identifier we are interested on. The second parameter is the expiration time. This means that the lock will be automatically released after 5 minutes.
if(!$lock->get()) {
return response([
'message' => 'Another user deploys the site at the moment.'
], Response::HTTP_BAD_REQUEST);
}Here we try to acquire the lock. Think of it as getting the key to unlock the lock. If we can not get it, it means that another one did. So the first time, the first process will not enter the if statement, because it will just get it. So that condition will be false. Which means that the first user/process can normally execute the code below.
$lock->release();Here we release manually the lock after the deploy. Maybe the deploy finished a lot earlier than 5 minutes, so why to keep the lock? We release it and the next process can start the procedure again, and deploy the same site.
Hopefully that makes sense!
Laravel also provides us some shortcuts for the above thing. I will be honest, I am not a fan. I find the above to be super clean and understandable. If you know the concept, there is almost zero mental effort for everyone to understand the code. So I will stick to that.
One step further
The above example is really good one to get the concept. But that can be improved! What I mean by that? You will probably dispatch the deploying logic to a job instead of executing straight on the controller. This is preferable for better UX, faster responses and more.
So that would change to something like (without any locking yet):
public function deploy(Site $site)
{
Gate::authorize('deploy', $site);
DeploySiteJob::dispatch($site);
return response([
'success' => true
]);
}Again, this is problematic as before. We only want one deploy per time, and inform the user if another deployment takes place.
This looks tricky tho, because what we actually want to do is to
- Initialise the locking on the controller
- Release it when Job finishes
We can! Laravel makes that extremely easy:
On our Controller:
public function deploy(Site $site)
{
Gate::authorize('deploy', $site);
$lock = Cache::lock("site_deploy_$site->id", 60 * 5);
if(!$lock->get()) {
return response([
'message' => 'Another user deploys the site at the moment.'
], Response::HTTP_BAD_REQUEST);
}
DeploySiteJob::dispatch($site, $lock->owner());
return response([
'success' => true
]);
}On our Job:
public function __construct(
private readonly Site $site,
private readonly string $lockOwner
)
{
//
}
public function handle(): void
{
// deploy process....
// $this->site->deploy();
// more..
Cache::restoreLock("site_deploy_$this->site->id", $this->lockOwner);
}Does that make sense? Let's analyse that:
DeploySiteJob::dispatch($site, $lock->owner());We dispatch our job passing the lock's owner here. Lock's owner is a random string actually, an identifier for our lock. Whoever has this owner thing, owner token let's say, can release the lock!
Cache::restoreLock("site_deploy_$this->site->id", $this->lockOwner);
Since we have our owner token, on the job now we are release the lock. And the procedure can start again.
That's extremely cool and powerful.
Cool things to know
- If we have our Laravel app on multiple servers through load balancing, we need to make sure that all the server have same access on the same Cache store where we save the locks. For example, you should have a central Redis store (btw Redis works wonders for that)
- Official supported databases for locking: memcached, redis, dynamodb, database, file, or array.
- Atomic Locking is just a fancy phrase. At the end of the day it's just a boolean value for an identifier (that's the logic).
- "Atomic" comes from Database ACID, the first letter. It is about Atomicity, a property of database transactions. You can read more around on the Internet about that.
- Prefer to give your locking some extra "buffer" time to avoid the lock being expired while the actual code is still being executed. You can always release it manually after business logic.